python-爬取104人力銀行的職缺訊息

python-爬取104人力銀行的職缺訊息
(一).印出職缺內容
首先先以Google Chrome連到104人力銀行網站,隨意搜尋關鍵字,我先舉搜尋'Python'為例子。
接著網頁會加載搜尋到有關Python的職缺,按下F12進入開發者模式。
對著各個職缺名稱點選右鍵->檢查,會跳出該職缺內容的路徑。
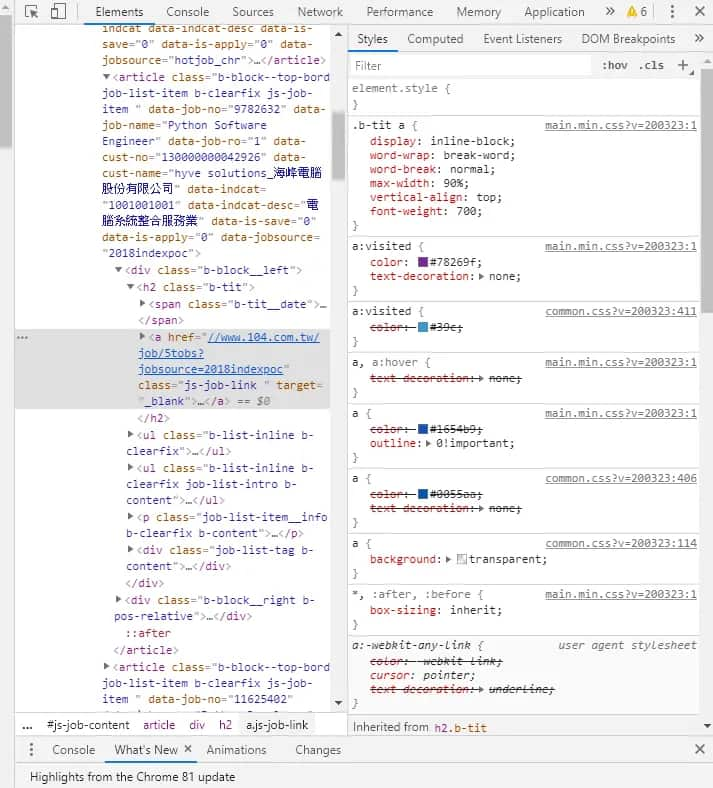
我們知道,所有職缺的子標籤都是在<div id="js-job-content">的標籤裡,而每個子標籤都叫做<article class="js-job-item">,這些資訊即可爬取個職缺內容囉。
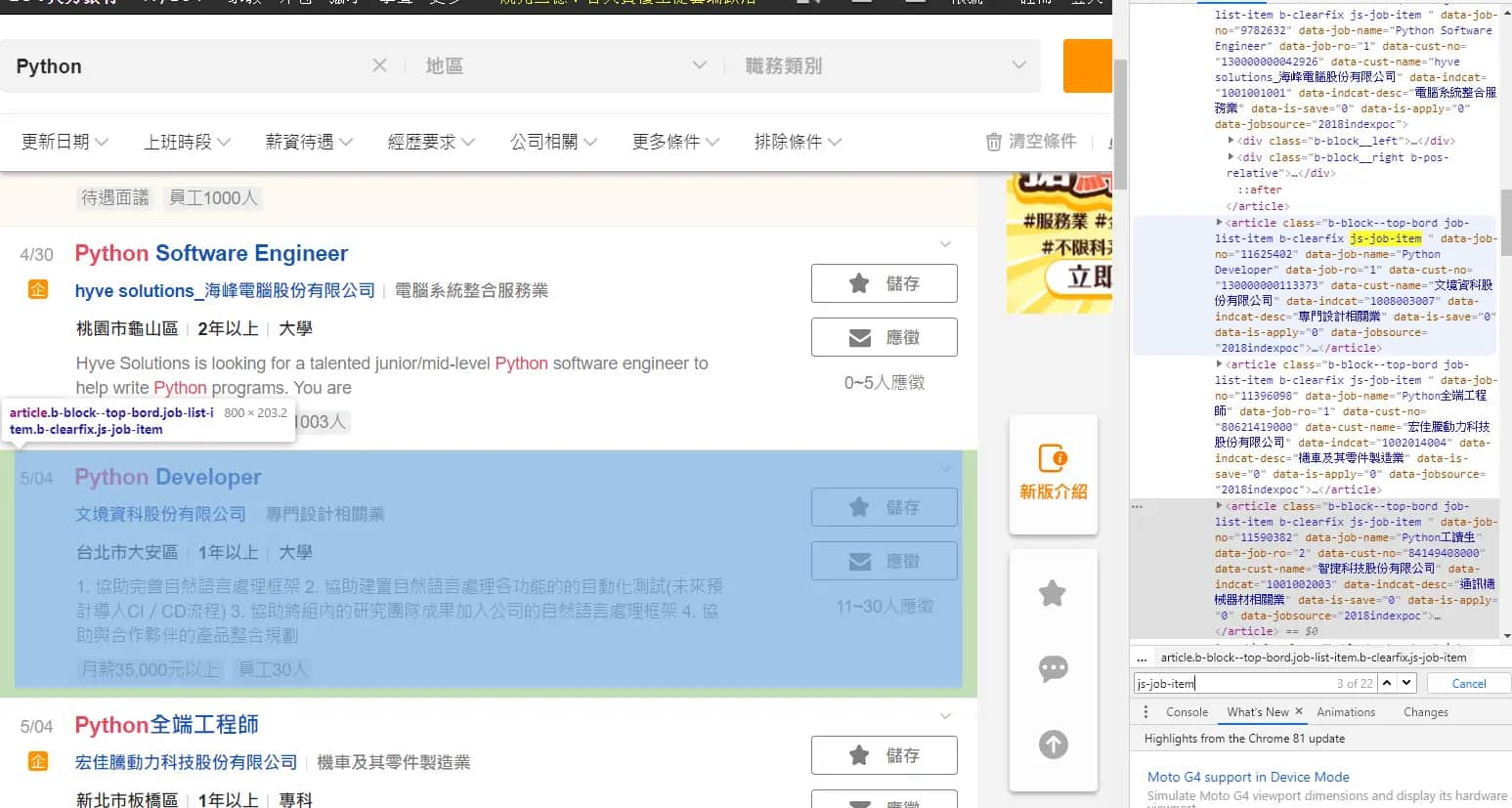
我只想要知道各個職缺名稱、公司名稱、地址、薪資、網址。
職缺名稱在data-job-name裡 ,也在<a>標籤的class"js-job-link"裡
公司名稱在data-cust-name裡
地址在<ul>標籤的class="job-list-intro"的<li>標籤裡
薪資在<span>標籤的class="b-tag--default:裡
網址在<a>標籤的href裡
程式碼如下:
#印出各個職缺內容
import requests
import bs4
url = 'https://www.104.com.tw/jobs/search/?keyword=python&order=1&jobsource=2018indexpoc&ro=0'
htmlFile = requests.get(url)
ObjSoup=bs4.BeautifulSoup(htmlFile.text,'lxml')
jobs = ObjSoup.find_all('article',class_='js-job-item') #搜尋所有職缺
for job in jobs:
print(job.find('a',class_="js-job-link").text) #職缺內容
print(job.get('data-cust-name')) #公司名稱
print(job.find('ul', class_='job-list-intro').find('li').text) #地址
print(job.find('span',class_='b-tag--default').text) #薪資
print(job.find('a').get('href')) #網址
print('='*70)
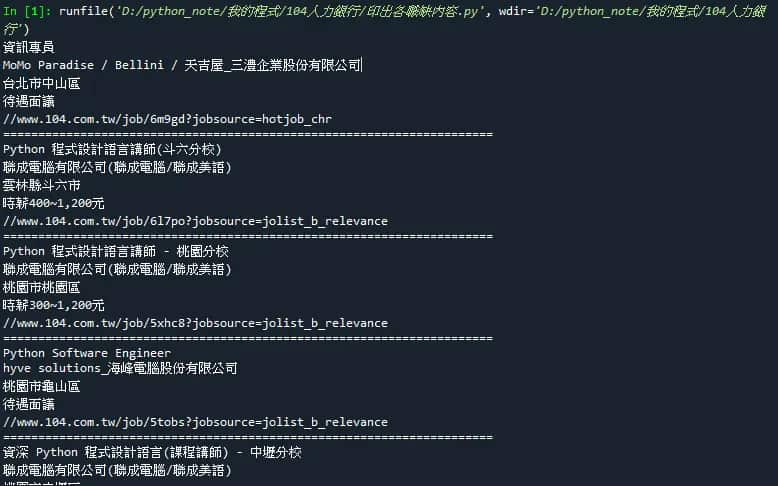
執行結果:
(二)資料存取,將爬取資料存成csv檔
光是印出職缺內容還不夠,我希望能存成CSV格式,使用EXCEL來搜尋比較方便。
這裡我使用CSV方式來做資料存取的動作。
程式碼如下:
#將各個職缺內容存到csv檔
import requests
import bs4
import csv
url = 'https://www.104.com.tw/jobs/search/?keyword=python&order=1&jobsource=2018indexpoc&ro=0'
htmlFile = requests.get(url)
ObjSoup=bs4.BeautifulSoup(htmlFile.text,'lxml')
jobs = ObjSoup.find_all('article',class_='js-job-item') #搜尋所有職缺
fn='104人力銀行職缺內容.csv' #取CSV檔名
columns_name=['職缺內容','公司名稱','地址','薪資','網址'] #第一欄的名稱
with open(fn,'w',newline='',) as csvFile: #定義CSV的寫入檔,並且每次寫入完會換下一行
dictWriter = csv.DictWriter(csvFile,fieldnames=columns_name) #定義寫入器
dictWriter.writeheader()
for job in jobs:
job_name=job.find('a',class_="js-job-link").text #職缺內容
job_company=job.get('data-cust-name') #公司名稱
job_loc=job.find('ul', class_='job-list-intro').find('li').text #地址
job_pay=job.find('span',class_='b-tag--default').text #薪資
job_url=job.find('a').get('href') #網址
dictWriter.writerow({'職缺內容':job_name,'公司名稱':job_company,
'地址':job_loc,'薪資':job_pay,'網址':job_url})
執行結果:
會跑出一個104人力銀行職缺內容.csv檔案
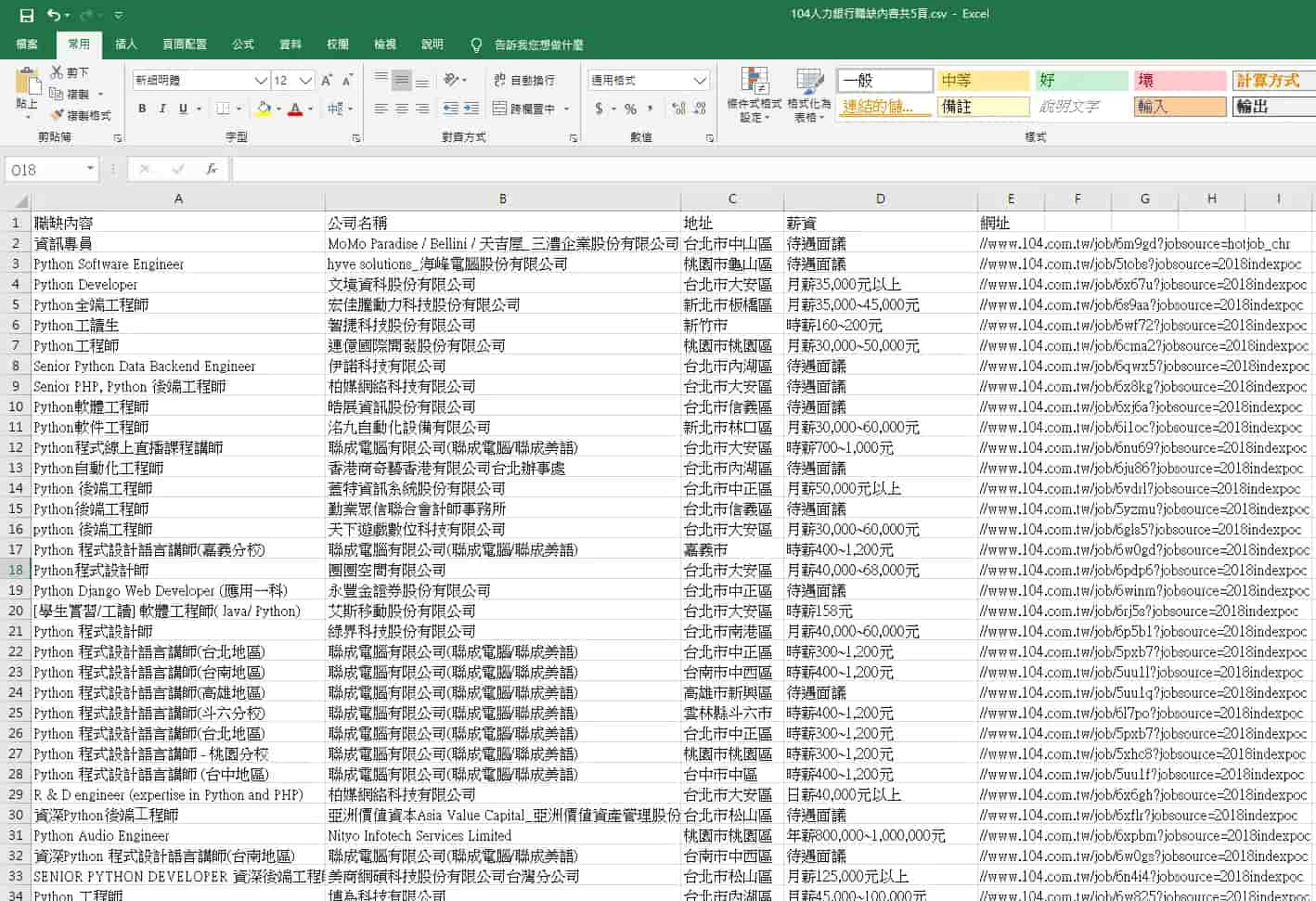
這樣子我們就完成資料的存取囉!
(三)連續爬取多頁,並存成CSV檔
讀者可能會發現,明明還有好幾頁,為什麼只存第一頁的職缺資料而已。
當你試著在網站上往下滾輪到底,網站會自動載入第二頁的職缺內容,這是使用了Ajax的加載技術。觀察網址發現,網址會自動變成含有page=2,所以我們知道,如果要爬取下一頁的資訊,只需要把這個跑出來的網址宣告給url參數就好了。
因為會大量搜尋網站上的資料,故每一次換頁時需加上等待時間time.sleep()較佳。
現在筆者試著把取前5頁的職缺資訊
程式碼如下:
#爬取5頁的職缺內容,將各個職缺內容存到csv檔
import requests
import bs4
import csv
import random,time
url_A ='https://www.104.com.tw/jobs/search/?ro=0&kwop=7&keyword=python&order=15&asc=0&page='
url_B = '&mode=s&jobsource=2018indexpoc'
all_job_datas=[]
for page in range(1,5+1):
url = url_A+str(page)+url_B
print(url)
htmlFile = requests.get(url)
ObjSoup=bs4.BeautifulSoup(htmlFile.text,'lxml')
jobs = ObjSoup.find_all('article',class_='js-job-item') #搜尋所有職缺
for job in jobs:
job_name=job.find('a',class_="js-job-link").text #職缺內容
job_company=job.get('data-cust-name') #公司名稱
job_loc=job.find('ul', class_='job-list-intro').find('li').text #地址
job_pay=job.find('span',class_='b-tag--default').text #薪資
job_url=job.find('a').get('href') #網址
job_data={'職缺內容':job_name,'公司名稱':job_company,
'地址':job_loc,'薪資':job_pay,'網址':job_url}
all_job_datas.append(job_data)
time.sleep(random.randint(1,3))
fn='104人力銀行職缺內容共5頁.csv' #取CSV檔名
columns_name=['職缺內容','公司名稱','地址','薪資','網址'] #第一欄的名稱
with open(fn,'w',newline='') as csvFile: #定義CSV的寫入檔,並且每次寫入完會換下一行
dictWriter = csv.DictWriter(csvFile,fieldnames=columns_name) #定義寫入器
dictWriter.writeheader()
for data in all_job_datas:
dictWriter.writerow(data)


