python-selenium的介紹及定位元素方法
selenium 是一種爬取資料的一種插件、方法 ,其功能很強大,它的功能是真的自動開啟瀏覽器來執行動作,就好像是被遠端遙控一樣。 我認為算是比較穩定、比較不會出錯的爬蟲方法。以下我將介紹如何安裝這個套件以及地位元素的方法。

python-selenium的介紹及定位元素方法
(一)selenium的介紹與安裝
selenium 是一種爬取資料的一種插件、方法 ,其功能很強大,它的功能是真的自動開啟瀏覽器來執行動作,就好像是被遠端遙控一樣。
我認為算是比較穩定、比較不會出錯的爬蟲方法。以下我將介紹如何安裝這個套件以及地位元素的方法。
這套插件要如何安裝呢?
首先在python程式下輸入:
pip install selenium只安裝這個插件是無法使用的,還必須另外下載selenium驅動程式。
第二步是到 selenium官網,畫面往下移到約莫中間的地方,有個Browsers。
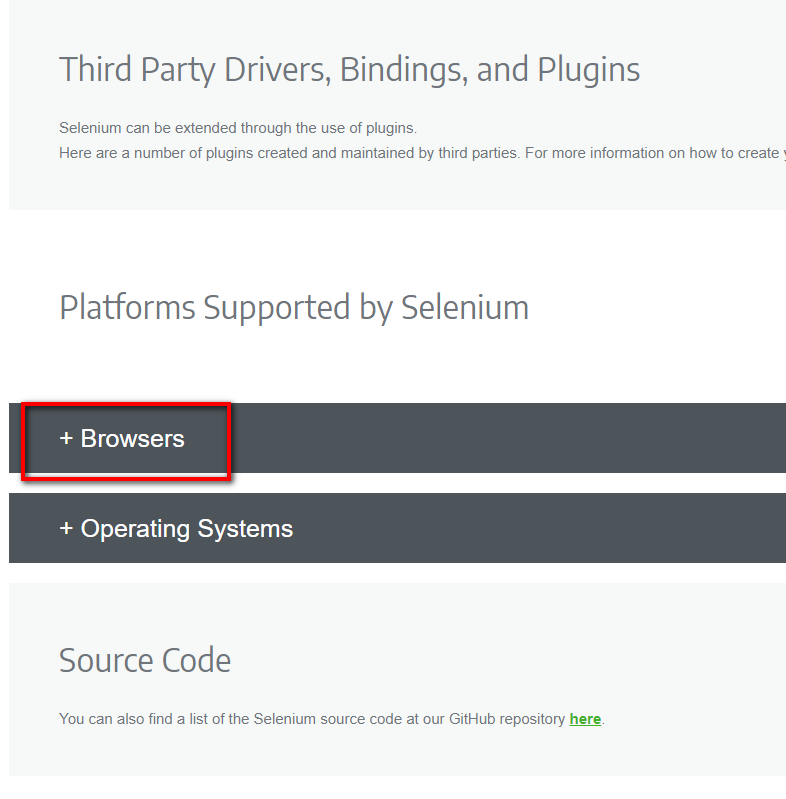
這個意思是要驅動哪一個瀏覽器來進行程式,一般比較常見的驅動程式是選用Firefox和Chrome的,我本身比較習慣使用Chrome,擇其一下載就好囉。
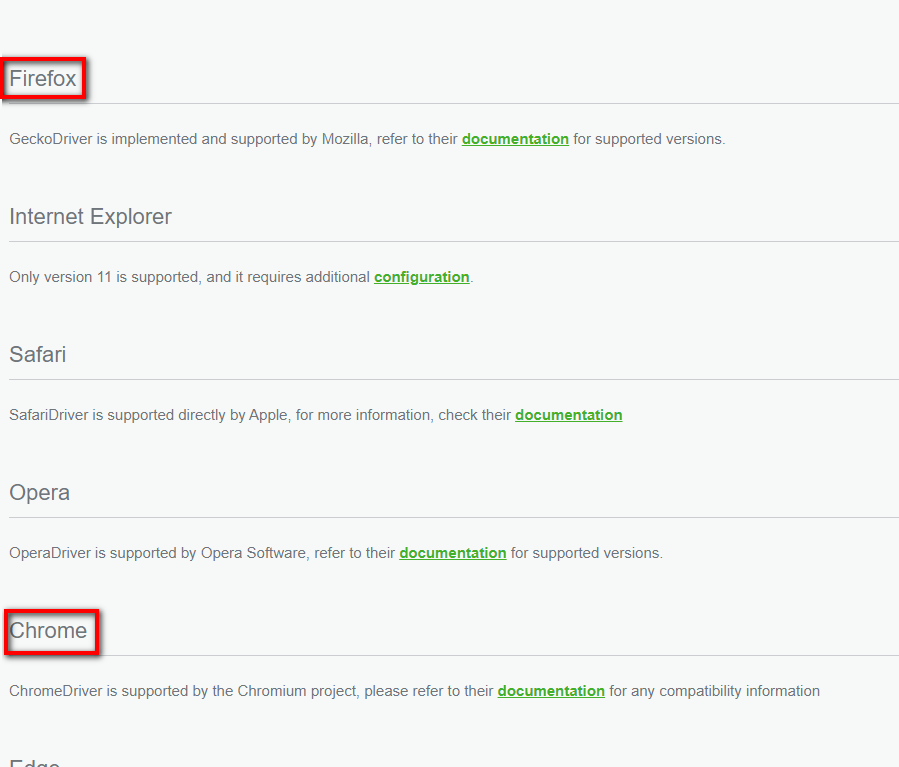
這個意思是要驅動哪一個瀏覽器來進行程式,一般比較常見的驅動程式是選用Firefox和Chrome的,我本身比較習慣使用Chrome,擇其一下載就好囉。
以Chrome為例,點擊網站進去,會要選擇下載哪一個版本,這時請檢查一下自己的Chrome的版本是什麼。
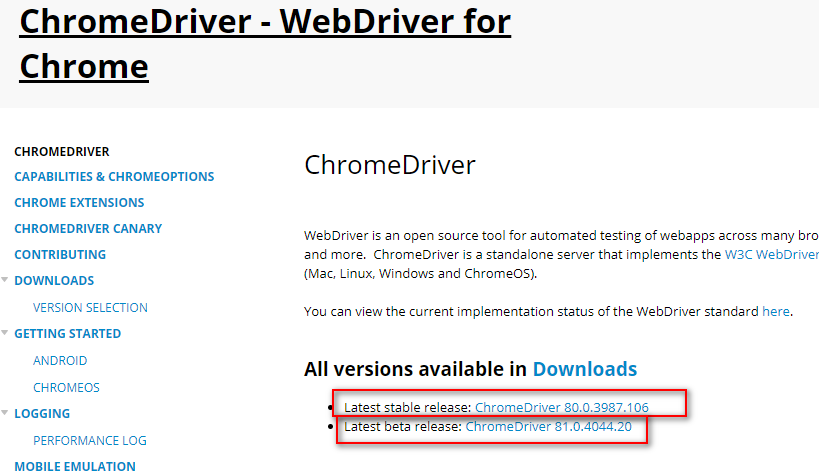
查詢Chrome版本的方法為右上角… →設定→跳出一個畫面後,在左欄的最下方-關於Chrome就有囉!
接著就可以開始安心下載了。
下載的位置請幫到簡單的位置就好,比如D:\geckodriver 下
(二)selenium語法使用
我先以簡單的程式碼當例子講解:
#驅動瀏覽器
from selenium import webdriver
driverpath = 'D:\geckodriver\chromedriver.exe'
browser = webdriver.Chrome(executable_path=driverpath)其中driverpath就是你放置驅動程式的路徑及檔案,如果讀者是放在其他地方,請自行修改。
執行程式後,如果有跳出一個空的chrome瀏覽器代表你成功了。
接下來想要連上某個網站的話…
程式碼如下:
#連上網站
from selenium import webdriver
driverpath = 'D:\geckodriver\chromedriver.exe'
browser = webdriver.Chrome(executable_path=driverpath)
url = 'https://tw.yahoo.com/'
browser.implicitly_wait(5)
browser.get(url)這裡多出了browser.implicitly_wait(5)是因為,瀏覽器開啟時需要一些時間,必須等到瀏覽器開好,才有辦法去get網站,如果沒有等待5秒(或是更少、可自行決定)的話,程式將會出錯。
輸出結果就是跳出的瀏覽器自動可以連上yahoo的網站囉。
接下來就是尋找元素的方法了。
(三)selenium搜尋元素的方法介紹
找元素的方法有:
find_element_by_id('名稱')
find_element_by_class_name('名稱')
find_element_by_ name('名稱')
find_element_by_ css_selector('名稱')
find_element_by_partial_link_text('名稱')
find_element_by_link_text('名稱')
find_element_by_tag_name('名稱')
注意,以上都是只找"第一個"符合的內容就會停止搜尋了。
如果要找全部符合內容的話,就如下:
find_elements_by_id('名稱')
find_elements_by_class_name('名稱')
find_elements_by_ name('名稱')
find_elements_by_ css_selector('名稱')
find_elements_by_partial_link_text('名稱')
find_elements_by_link_text('名稱')
find_elements_by_tag_name('名稱')
結果會傳回串列!
那這七個找元素方法個別是什麼意思,以下一個一個介紹一下:(我都省略 find_elements_by )
id:找符合id的元素
例:
某網頁原始碼節錄...
========================================================
<div id="news">大家好</div>
<div id="news">我是落葉</div>
========================================================
於python輸入:find_element_by_id('news').text
輸出結果:
大家好
於python輸入:find_elements_by_id('news').text
輸出結果:
[大家好,我是落葉]class_name:找符合Class的元素
例:
某網頁原始碼節錄...
========================================================
<div class="news">大家好</div>
<div class="news">我是落葉</div>
========================================================
於python輸入:find_element_by_class_name('news').text
輸出結果:
大家好
於python輸入:find_elements_by_class_name('news').text
輸出結果:
[大家好,我是落葉]name:找符合name屬性的元素
例:
某網頁原始碼節錄...
========================================================
<div name="news">大家好</div>
<div name="news">我是落葉</div>
========================================================
於python輸入:find_element_by_name('news').text
輸出結果:
大家好
於python輸入:find_elements_by_name('news').text
輸出結果:
[大家好,我是落葉]css_selector:找符合 css_selector的元素
這個稍微複雜點,若是在Chrome瀏覽器下,請對著想要爬取的句子、物件、圖片點選右鍵->檢查
接著他會跑出開發者模式的視窗在右邊,該區域會有灰色的底顯示著,請用滑鼠指著它,接著你會看到你要排取的句子、物件、圖片會顯示一串文字。
我拿台灣大學網站為例子,如下圖
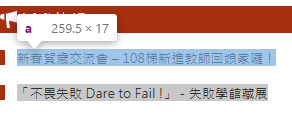
有顯示a 這個字,這個就是 css_selector 會定位到的資料
例:
於python輸入:find_element_by_css_selector('a').text
輸出結果:
新春賀歲交流會 – 108梯新進教師回娘家囉!
於python輸入:find_elements_by_css_selector('a').text
輸出結果:
[新春賀歲交流會 – 108梯新進教師回娘家囉!,「不畏失敗 Dare to Fail !」-失敗學館藏展]partial_link_text :找出內容有text的<a>元素
例:
某網頁原始碼節錄...
========================================================
<a href="aaa.html">abcd</a>
<a href="bbb.html">abcdefg</a>
========================================================
於python輸入:find_element_by_partial_link_text('abc').text
輸出結果:
abcd
於python輸入:find_elements_by_partial_link_text('abc').text
輸出結果:
[abcd,abcdefg]link_text :找出內容完全相同text的<a>元素
例:
某網頁原始碼節錄...
========================================================
<a href="aaa.html">abcd</a>
<a href="bbb.html">abcdefg</a>
========================================================
於python輸入:find_element_by_link_text('abcd').text
輸出結果:
abcd
於python輸入:find_elements_by_link_text('abcd').text
輸出結果:
[abcd]tag_name :找出標籤名稱的元素
例:
某網頁原始碼節錄...
========================================================
<a href="aaa.html">abcd</a>
<a href="bbb.html">abcdefg</a>
========================================================
於python輸入:find_element_by_tag_name('a').text
輸出結果:
abcd
於python輸入:find_elements_by_tag_name('a').text
輸出結果:
[abcd,abcdefg]以上是定位元素的方法,是不是很簡單呢!?



